Crash是什么
Crash其实就是当有些操作不被系统或者软件允许时,通过一些信号或者异常让进程中止的现象。当然,在收到信号或者异常时,也可以选择不处理让进程继续运行,但是一般不会这样做,因为后可能导致一些不可预知的后果。在OSX&iOS中,Crash一般由以下两种信号产生。
Hardware-Generated Signals
硬件层面的信号(比如常见的野指针)最早是来自处理器的traps,然后会被Mach层捕获,从Mach异常转换为Unix信号,转换逻辑见代码(通用Mach和机器相关异常处理)
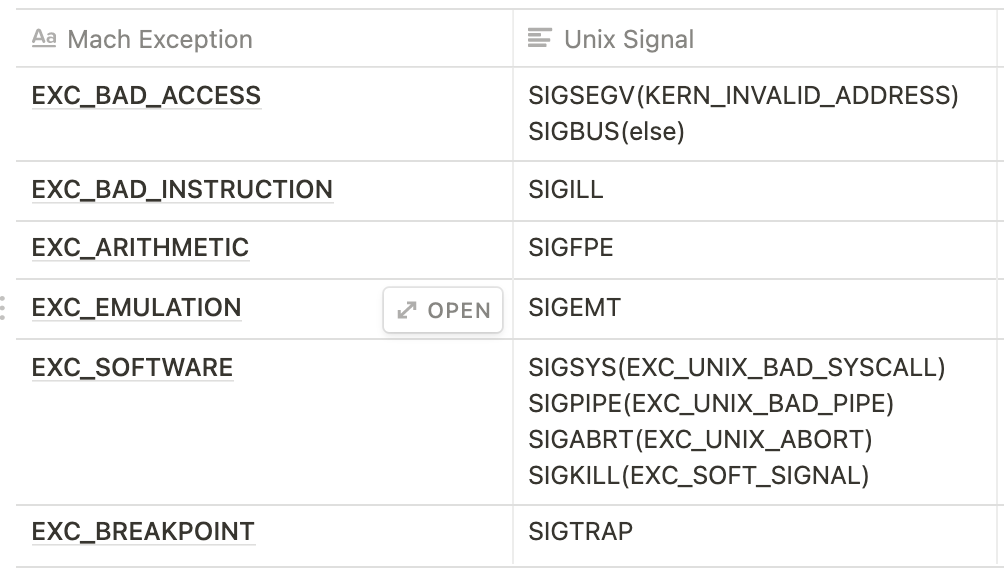
转换为Unix信号之后会统一调用threadsignal最终走到act_set_astbsd()。整个流程如下:
这里有个有趣的地方,就是通过代码我们发现,如果发生stack overflow,那么signal是SIGSEGV而不是SIGBUS。
1 | kern_return_t handle_ux_exception(thread_t thread, |
Software-Generated Signals
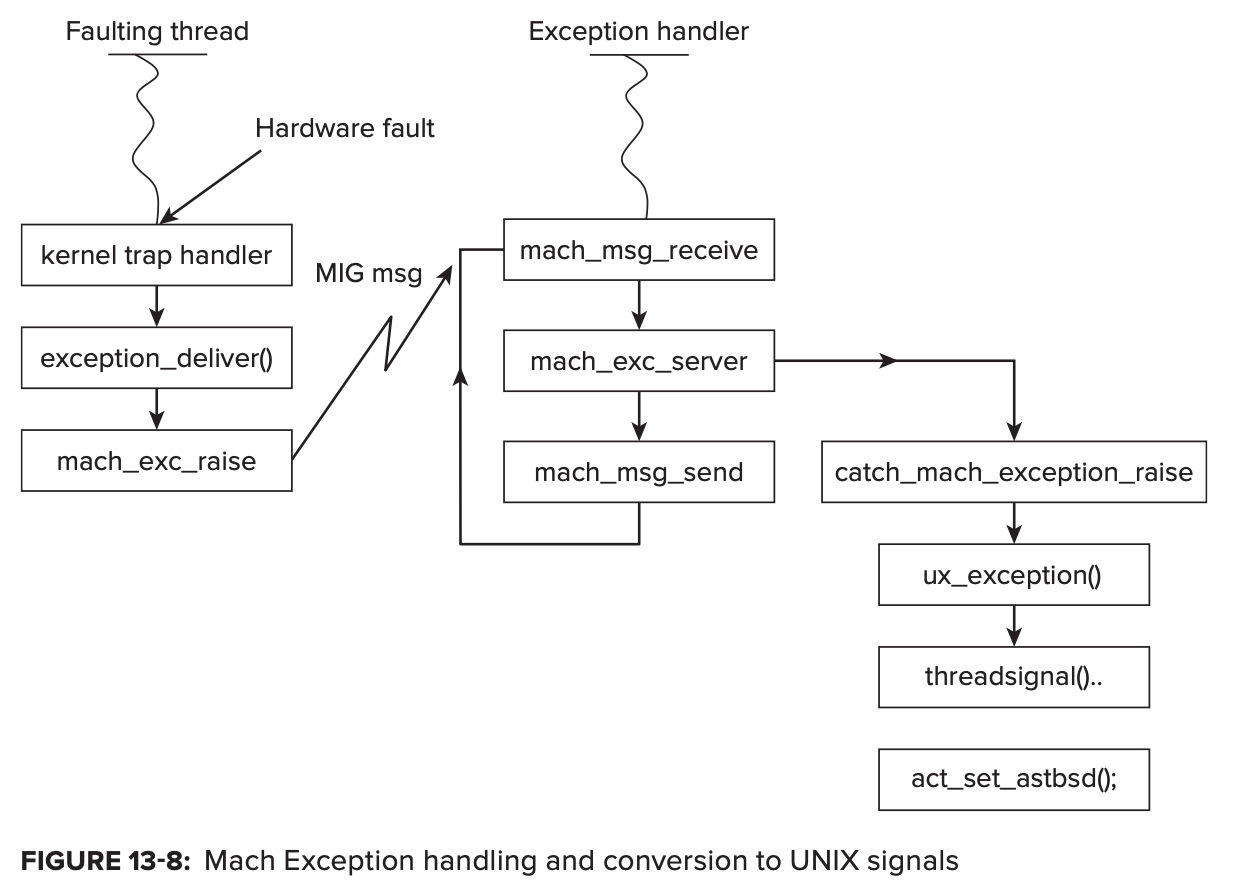
除了硬件产生的信号,其他产生的信号(越界,竞态等的软件产生的信号)一般都来自kill(2)或者pthread_kill(2)两个API,最终也会走到act_set_astbsd()。
为了保持统一的处理机制,系统和用户产生的软件异常,会首先被转换Mach异常然后再转化为Unix信号。
Crash的捕获
通过上面的简单分类,我们可能会觉得只要捕获Unix信号可以捕获所有Crash了?其实不是。
如果只捕获Mach异常,不捕获Unix信号,那么遇到
EXC_CRASH这种异常就可能出问题。1
2
3
4PLCrashReporter
/* We still need to use signal handlers to catch SIGABRT in-process. The kernel sends an EXC_CRASH mach exception
* in an uninterruptable wait. Thus, we fall back on BSD signal handlers for SIGABRT, and do not register for
* EXC_CRASH. */如果只捕获Unix信号,不捕获Mach异常,可能会漏掉一些错误,因为不是所有Mach异常都会转换为Unix信号。
这点通过上面的映射表和下面的所有Mach异常定义可以看出来(比如,
EXC_GUARD在上表中就没有找到对应的映射Unix Signal)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
/* Code contains kern_return_t describing error. */
/* Subcode contains bad memory address. */
/* Illegal or undefined instruction or operand */
/* Exact nature of exception is in code field */
/* Emulation support instruction encountered */
/* Details in code and subcode fields */
/* Exact exception is in code field. */
/* Codes 0 - 0xFFFF reserved to hardware */
/* Codes 0x10000 - 0x1FFFF reserved for OS emulation (Unix) */
/* Details in code field. */
/* Exact resource is in code field. */
所以,正确的捕获Crash方式应该是两种方式同时采用,互相补充。
KSCrash捕获原理
我们拿开源的KSCrash来分析,看下针对Crash的捕获需要做些什么。
KSCrash对Crash的捕获分成了几种类型
- Mach kernel exceptions
- Fatal signals
- C++ exceptions
- Objective-C exceptions
- Main thread deadlock (experimental)
主线程死锁暂时不看,因为机制完全不一样(通过监听主线程完成类似watchdog的工作)。同时我们注意到除了Mach异常和Unix信号,还单独拆分了C++异常和OC异常(NSException),那是因为C++异常和OC属于上层语言提供的异常,可以被catch和处理,当然也有可能转化为底层信号,但是他们附带的信息会更多,比如NSException抛出时会把原因,用户信息,堆栈等都直接抛出,而捕获底层信号时获取堆栈反而比较麻烦。
Mach kernel exceptions
Mach的异常捕获,依赖Mach层提供的API,从代码流量可看出大致需要做哪些:
1 | static bool installExceptionHandler() { |
其中处理现场和获取机器堆栈等信息部分太长,有兴趣可以自己查看。总体看下来大致两个步骤:1. 注册一个端口接收异常 2. 新建一个线程监控和处理异常
Fatal signals
1 | static bool installSignalHandler() { |
Unix的信号捕获依赖各个类型信号的注册 sigaction ,而其处理过程和之前类似。有意思的是处理完之后,会直接raise,raise的作用是给当前线程发一个信号,不知道为什么注释里写着技术上不允许。
C++ exceptions
1 | // std::set_terminate指定处理 |
C++的异常主要依靠std::set_terminate ,中间处理的时候用try{ throw; } catch {} 来获取异常的信息。
Objective-C exceptions
OC的异常比较容易,也都很熟悉,使用NSSetUncaughtExceptionHandler 即可,就不贴代码了。
Crash的符号化
Crash的符号化前提是,先得有一个符号表dSYM 和crash日志。
生成dSYM
Xcode的Build Setting中,需要设置:
- Generate Debug Symbols(
GCC_GENERATE_DEBUGGING_SYMBOLS) = YES - Debug Infomation Format(
DEBUG_INFORMATION_FORMAT) = DWARF with dSYM File
当开启了上述配置,生成的二进制文件中将不再包含符号信息,取而代之的是一个单独的dSYM文件。当发生crash时,crash report里面展示的将是各种对象和方法的内存地址,必须配合dSYM文件才能将真实调用信息解析出来。
获取Crash Report
- TestFlight用户或者允许了发送诊断信息的Appstore用户,可以在Xcode→Window→Organizer→Crash中看到崩溃信息。
- 本地测试机器,可以在手机的Setting→Privacy→Analytics & Improvements →Analytics Data→
_ 找到。 - 自己捕获Crash然后上报(Bugly, KSCrash, PLCrashReporter…)
解析Crash Report
- 如果是在Xcode→Window→Organizer→Crash中看到的Crash,只要把dSYM文件下载到本地机器,可以直接在Organizer中symbolicate
如果是从手机中Analytics Data导出的报告或者自己上报的crash,可以将报告下载下来,按照下面步骤解析。
1
2
3
4
5//找到命令行工具symbolicatecrash
find /Applications/Xcode.app -name symbolicatecrash -type f
//将symbolicatecrash+dSYM+Crash Report放到一起,假设tmp目录下。
//解析生成crash log
./symbolicatecrash ./xxx.ips ./AppName.app.dSYM > crash.log单行Crash解析
Crash Report中除了堆栈调用外,最底下还有镜像的各种信息,拿下面这个举例子,找到想要解析的行,取出想要解析的地址,再找到对应的镜像加载地址和架构。

拿到这些信息后,可以按照固定格式调用
atos1
atos -arch <BinaryArchitecture> -o <PathToDSYMFile>/Contents/Resources/DWARF/<BinaryName> -l <LoadAddress> <AddressesToSymbolicate>
用一个最近的例子说明,我们的crash采集系统有的时候会堆栈解析不出来,大概长这样
1
8 IBUWireless 0x0000000103813788 void* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void (MyThread::*)(), MyThread*> >(void*) + 12452532
我尝试用atos解析,还是能正常解析的(XXXXX是打码部分),所以我们的crash采集系统还有待改进。
1
2% atos -arch arm64 -o IBUWireless.app.dSYM/Contents/Resources/DWARF/IBUWireless -l 0x101130000 0x0000000103813788
% __44-[XXXXX updateCell:]_block_invoke (in IBUWireless) (XXXXXX.m:0)
Crash的分析
要分析Crash,先要了解Crash Report的内容组成
Crash Report的组成
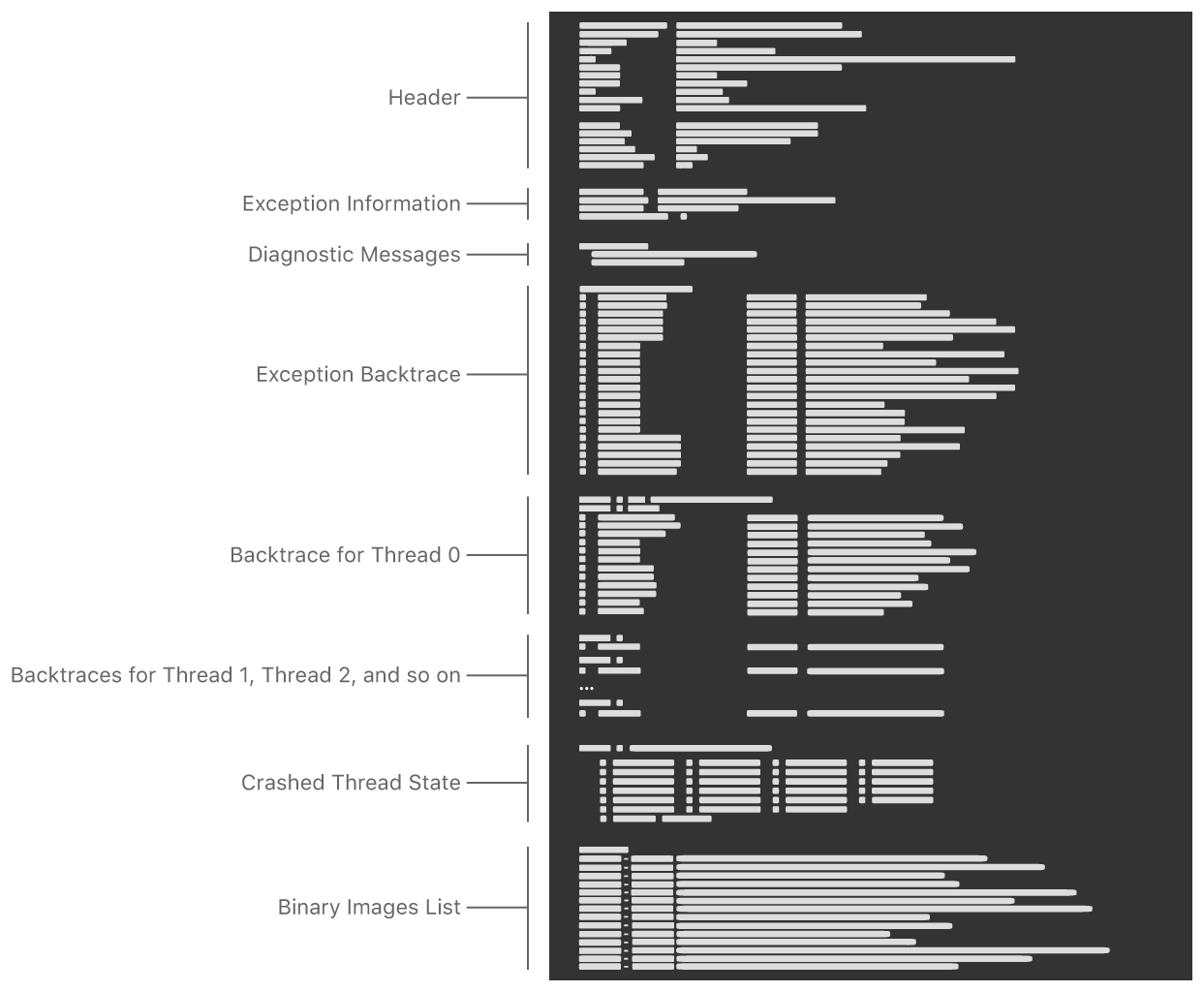
头部信息
头部信息一般包含以下字段:
Incident Identifier: 唯一标识,不同report不一样。CrashReporter Key: 唯一设备标识,同一台设备的report这个值是一样的,抹除设备会重制这个值。Beta Identifier: 只有Testflight有,结合设备和运营商的唯一标识。Hardware Model: 型号Process: 进程Path: 可执行文件的路径Identifier: BundleIDVersion: build号和版本号的结合AppStoreTools: Xcode版本AppVariant: app thinning产生的字段Code Type: CPU结构,ARM-64,ARM,X86-64, orX86.Parent Process: 父进程IDDate/Time: 时间信息Launch Time: 启动时间OS Version: 系统版本
异常信息
Exception Type: Mach的异常(Unix信号)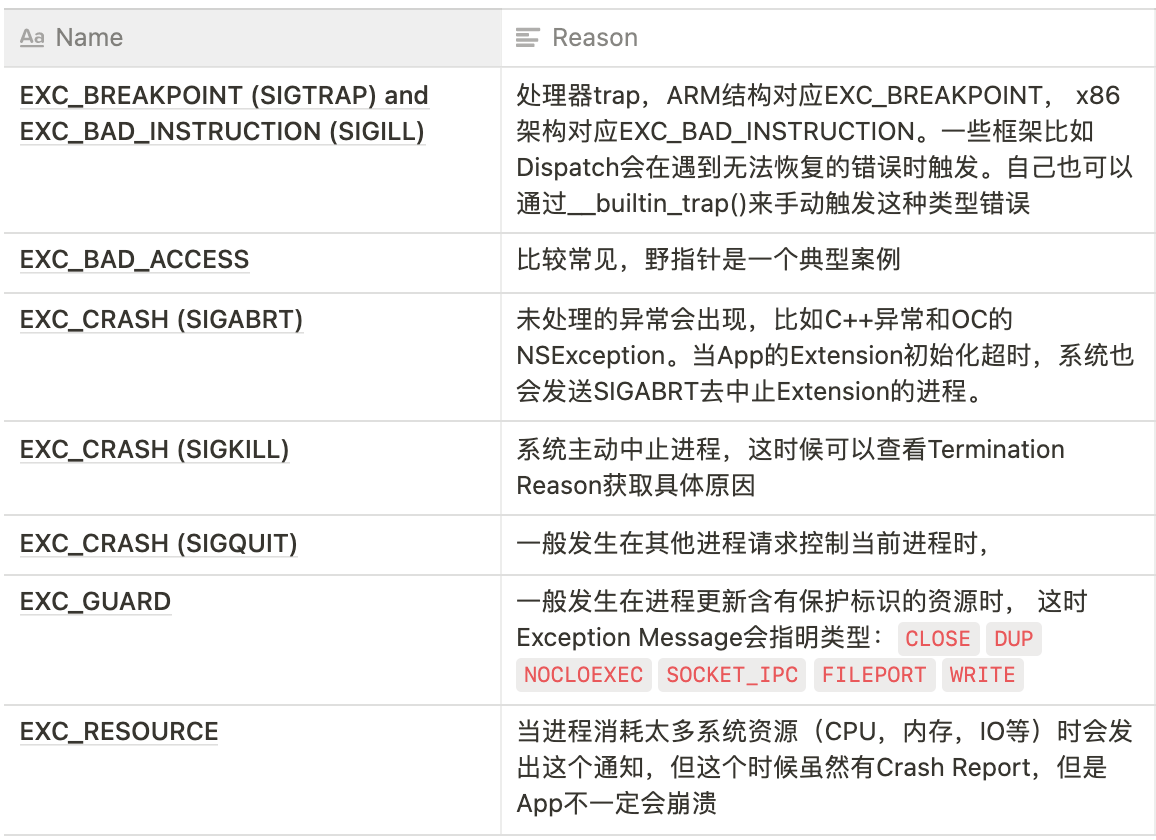
Exception Codes: 处理器特有标识,一般没啥用Exception Subtype: 异常的描述,有些Exception Message: 额外的描述信息Termination Reason: 操作系统中止进程时带上的具体原因,常见的case如下Triggered by ThreadorCrashed Thread: 崩溃的线程,大部分情况只看崩溃线程的堆栈就就能定位问题
诊断信息
Application Specific Information: 在 OC和C++ 异常情况下,这里一般有软件层抛出的具体错误信息,能很快定位问题,比如1
Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '-[XXXX method]: unrecognized selector sent to instance 0x2834ac5d0'
Termination Description: 如果是watchdog杀死进程,则可能会有这个字段描述1
2
3Termination Description: SPRINGBOARD,
scene-create watchdog transgression: application<com.example.MyCoolApp>:667
exhausted real (wall clock) time allowance of 19.97 secondsVM Region Info: 内存原因的Crash会带上1
2
3
4
5VM Region Info: 0 is not in any region. Bytes before following region: 4307009536
REGION TYPE START - END [ VSIZE] PRT/MAX SHRMOD REGION DETAIL
UNUSED SPACE AT START
--->
__TEXT 0000000100b7c000-0000000100b84000 [ 32K] r-x/r-x SM=COW ...pp/MyGreatApp
崩溃堆栈
大部分情况,我们能通过崩溃堆栈找到错误原因。如果崩溃堆栈是系统线程,我们就需要借助别的手段。
主线程+其余所有堆栈
这里记录所有线程的堆栈,当崩溃堆栈不能直接指出原因时,我们可以查看崩溃那一刻,其他所有线程在做什么,寻找每个崩溃时多个线程的共同点,也许会有意外收获。
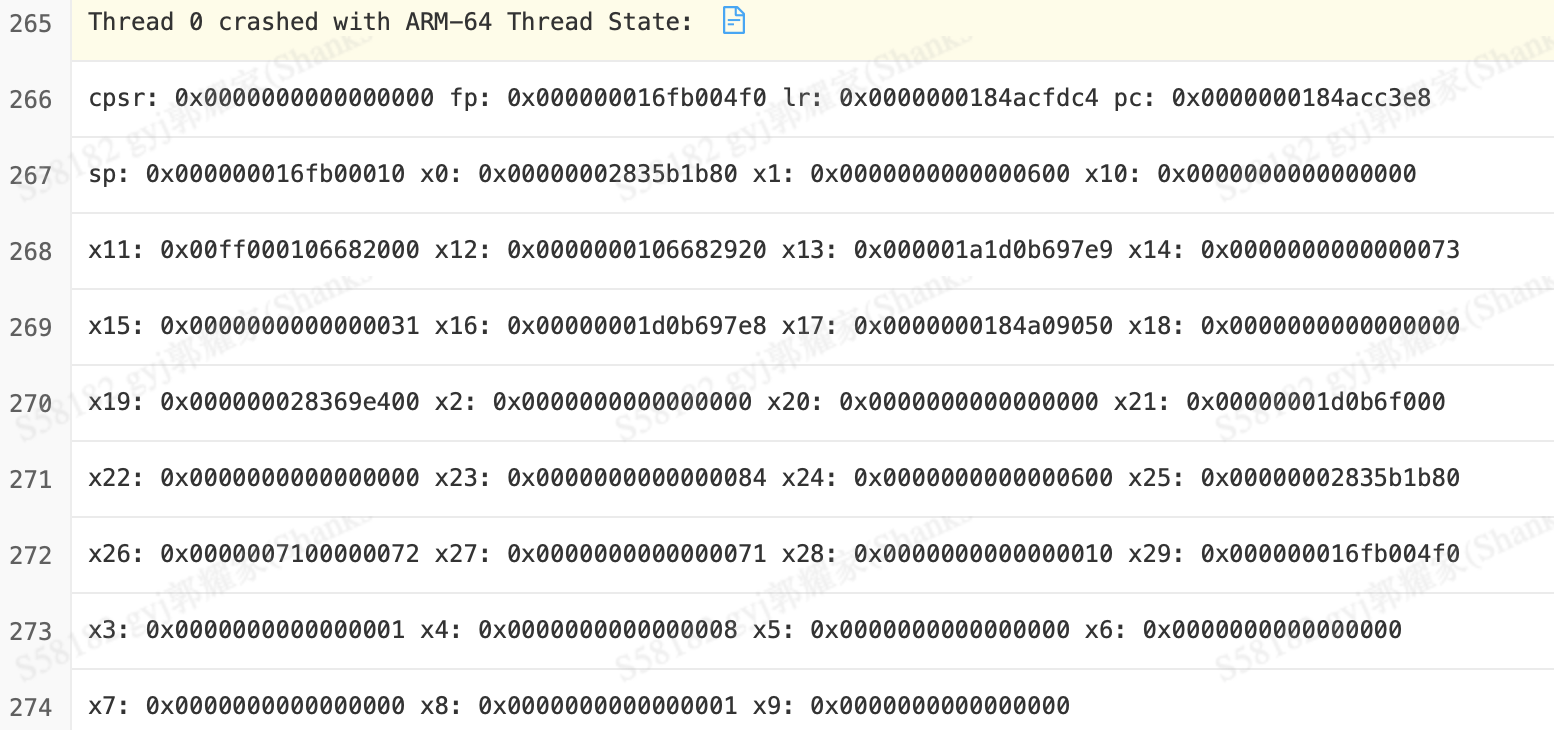
崩溃线程状态
这里记录了崩溃时,线程的状态,包括各个寄存器的值,一般用不到这里。但是一些难以定位的crash可能会借助这个来排查。(我自己也涉及不多-_-)
镜像列表
这里列举了所有镜像的信息
1 | //格式 起始地址-结束地址 名称 架构 uuid 路径 |
一般镜像用于解析堆栈,当然也可以用来判断是否越狱,比如如果出现一些典型的比如hookkeyboard.dylib 基本可以判断这台机器是越狱的。
常见Crash分析
一般的NSException或者C++异常很好定位,比如空指针,数组越界等,就不赘述。我们单独来看看内存类的Crash,因为这类Crash一般不容易复现和定位。
内存类错误一般表现为EXC_BAD_ACCESS (SIGSEGV) or EXC_BAD_ACCESS (SIGBUS),原因是访问了非法内存地址(对象内存已经释放但是指针还在),或者往只读的内存写等。
使用Xcode分析
Xcode提供了很多工具分析内存类的错误,Address Sanitize Undefined Behavior Sanitizer Thread Sanitizer 和 静态分析等,都有可能发现App运行中内存问题,如果发现,及时修复。
Crash Report分析
有的时候通过Xcode提供的工具不一定能完全复现问题,这时候我们要对Crash Report深入分析。
- 如果能从崩溃堆栈看出具体代码,能比较快定位。如果堆栈出现
objc_msgSend,objc_retain,objc_release,那这很可能是zombie对象。 内存类错误有的会在Crash Report中的
Exception Subtype指明原因,我们可以通过这个字段进一步定位发生错误的原因。
尝试通过寄存器还原现场
ARM中,lr存放方法调用的返回地址,通过还原lr中的代码调用,可以看到出错代码的调用入口。
拿一个真实的例子来看,通过
atos解析lr寄存器存的地址(XXX照样打码),这可能对分析问题会有帮助。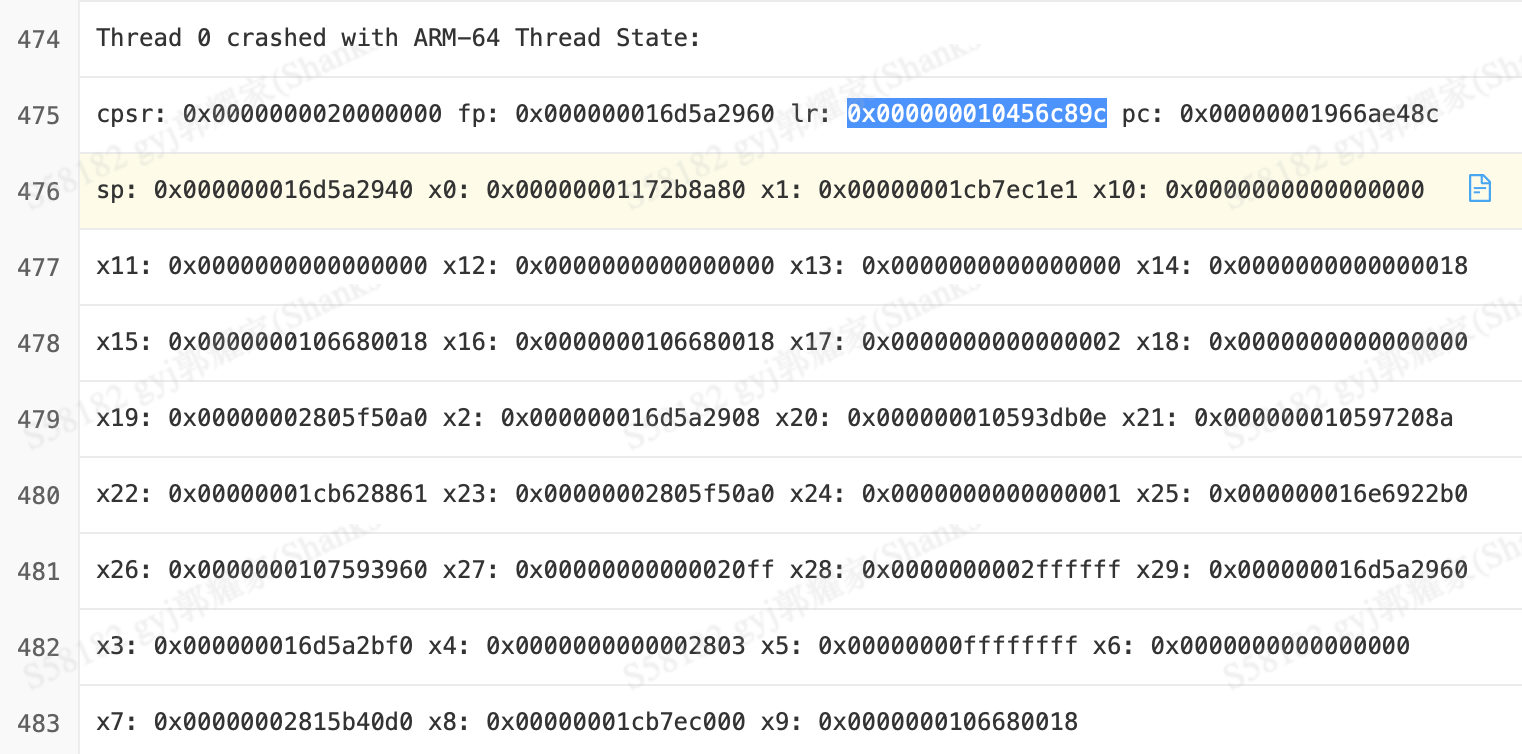
1
2% atos -arch arm64 -o IBUWireless.app.dSYM/Contents/Resources/DWARF/IBUWireless -l 0x101130000 0x000000010456c89c
-[XXXControlView1 topCustomContentView] (in IBUWireless) (XXXControlView1.m:671)通过崩溃用户的所有信息分析共性(操作系统,网络环境,语言,地区…),尝试复现
- 针对zombie代码,可以试试看实现一个线上的zombie机制,具体可以参考KSCrash中的KSCrashMonitor_Zombie.c的实现,大致原理就是hookNSObject和NSProxy的dealloc方法,当对象dealloc的时候,生成zombie代替原来对象,这样当下次再有该对象的dealloc消息过来,就可以判定为重复释放。
总结
总结一下,本次学习了Crash的生成,捕获,符号化和分析,但是真实的Crash还是有很多细节在里面,需要自己在实践中一步步感受。
参考文档
《Mac OS and iOS Internals》