什么是增量覆盖率
增量覆盖率,顾名思义,指的是每次代码改动的增量部分,开发自测的覆盖程度。
为什么需要增量覆盖率
大型项目为了持续保证代码和App的质量,需要对新引入代码进行审查,而在代码被合并进去之前(比如在code review阶段),增量覆盖率无疑是衡量开发对代码的自测重复程度的一个很好的指标。
代码覆盖率不是万能的,只能通过这个手段解决一部分明显通过自测就可以发现的问题。
增量代码覆盖率更偏向于开发使用,保证开发自测的充分程度。
怎么实现增量代码覆盖率
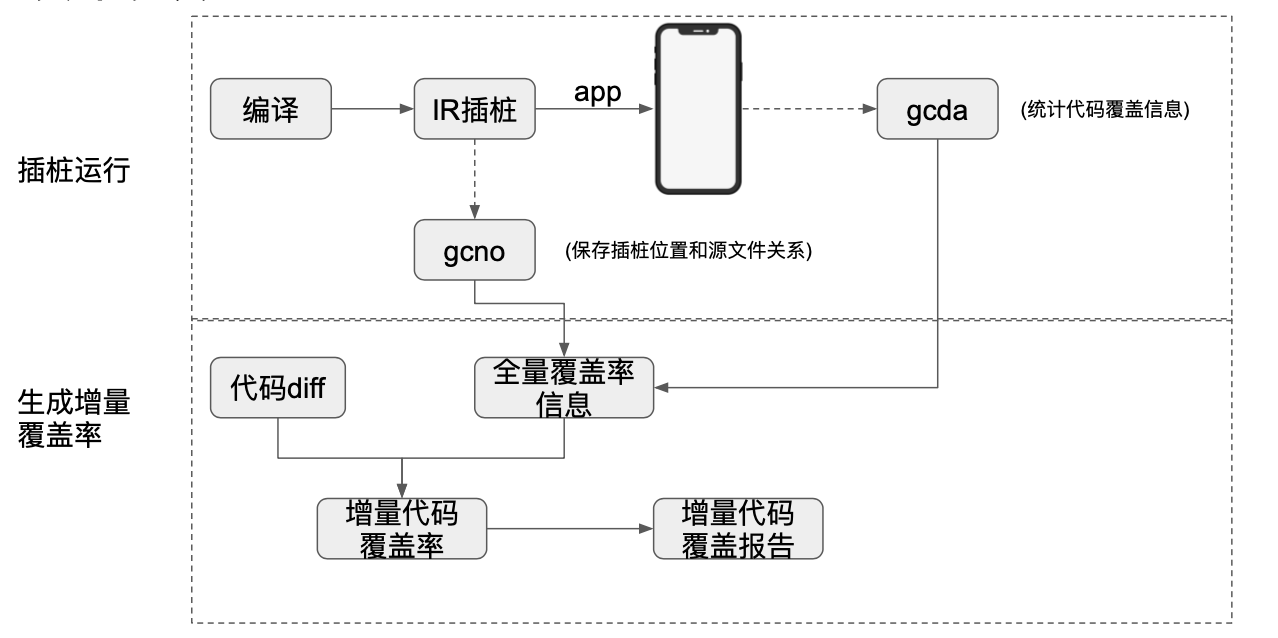
上图展示了基本的思路,主要分3步。
- 采集全量覆盖率
- 采集代码diff
- 根据代码diff和全量覆盖率过滤出增量覆盖率
采集全量覆盖率
全量覆盖率的采集,需要以下几步。
- 配置工程,使得能在运行时插桩产生覆盖率数据。
这里我们采用ruby脚本,每次需要的时候自动将配置加到工程里。需要注意的是,如果需要统计的不是主project而是依赖的子project,这个配置需要加到子的project中,因为这样子的project在编译时才能进行IR插桩。
1 | require 'xcodeproj' |
- 编译时采集gcno文件。
gcno包含了代码计数器和源码的映射关系,编译之后就会生成,具体目录如下。
不同架构下的编译产物目录根据PLATFORM_PREFERRED_ARCH不同而有所区别。
ps: OBJECT_FILE_DIR_normal和PLATFORM_PREFERRED_ARCH是Xcode编译时的环境变量,可以在运行xcodebuild时加上-showBuildSettings来查看所有环境变量。
1 | OBJECT_FILE_DIR_normal/PLATFORM_PREFERRED_ARCH |
- 运行时采集gcda文件。
gcda 记录了每段代码具体的执行次数,运行时产生,具体生成的目录需要自己指定。
1 |
|
在应用进入后台或者其他时机,可以选择主动调用__gcov_flush();来刷新本地的覆盖率数据。
在实际操作中,我们对模拟器和真机采取不同策略,模拟器因为沙盒目录其实就在mac本地,所以我们把gcda移动到我们的工作目录,编译后面生成覆盖率数据。真机我们选择将gcda上传到文件服务器,需要的时候从服务器拉下来辅助我们产生覆盖率数据。
1 | __gcov_flush(); |
当写入gcda内容时,如果发生写入的内容和文件中已有的内容有冲突,我们需要先删除本地原来的文件。将Apple源码中GCDAProfiling.c拷贝入自己的工程,对其中写入gcda代码作修改即可。
- 运行完触发全量覆盖率的生生成。
全量覆盖率的产生需要借助lcov和genhtml。lcov帮我们生成中间文件info,包含了所有的代码信息和覆盖率信息,genhtml帮我们将info文件转换成可视化html。
1 | 生成info文件 |
获取代码diff信息
Diff的获取相对简单,我们平常用git就可以拿到,如果用脚本,可以参考以下代码。
因为我们最终目的是增量覆盖率,所以我们在这里的核心其实就是拿到git记录中,行前面有+的行信息。
1 | import git |
获取增量覆盖率
现在我们拿到了全量覆盖率,同时也拿到了增量的代码行信息,怎么才能从中过滤出增量的代码覆盖率?
如果从最终的html入手去过滤,肯定是费时费力而且不稳定的,那么往前一步,我们在生成html之前有生成一个.info的文件,通过geninfo文档我们可以看出,这个文件包含了所有代码的信息以及代码运行的信息,这正是我们需要的。
1 | TN:<test name> |
所以我们只要解析出info文件,然后通过增量代码的行信息,从info文件中过滤出所有增量代码及其相关覆盖信息,就可以达到我们的效果。
- 解析info文件
这里参考我写的脚本Script
- 过滤出增量代码重新生成info。
这里在上一步的脚本中有相关代码,主要是标记info解析出的func是否是diff的方法,最终通过record的to_diff_info重新生成info文件。
- 运用genhtml重新生成html。
这一步还是和全量覆盖率中一致。
问题
在以上方案中,当多次运行代码,如果代码产生的覆盖率信息有冲突,__gcov_flush();的刷新策略不会将其覆盖,所以如果前后两次代码如果有冲突,很可能我们需要删掉App重新运行,这将是很费劲的。
所以我们将llvm的GCDAProfiling.c源码拿来,对覆盖刷新的部分做修改,如果有冲突则删除上一份保留最新的。
因为覆盖率插桩是编译器做的,实际运行时也会用到GCDAProfiling,所以我们这样做其实替换了插桩代码用到的GCDAProfiling。
总结
这里大致叙述了做增量覆盖率时的一些思路,想把整个流程做完善并且易于使用,还是需要结合自己工程和开发流程做一些工作,才能让这个工具易用方便。